![]()

Stop Prompting, Start Configuring
5 Hard Truths About the New AI-Native Data Stack
1. Introduction: The Death of the “Vibe-Based” Prompt
The prompt is dead; long live the configuration manifest. For the past two years, software engineering has been obsessed with “vibes”—the dark art of coaxing Large Language Models (LLMs) into compliance through polite prose and trial-and-error conversational requests. In the emerging era of AI-Driven Development (AIDD), this approach is not just inefficient; it is an architectural liability.
We must stop treating LLMs like pen pals and start treating them as deterministic systems that process information through statistical patterns and probabilities rather than human logic. The core problem is “attention dilution”: the tendency of models to lose the thread of instructions when buried in unstructured text. To build production-grade AI features, we are shifting from “talking” to “configuring,” moving toward a machine-centric data stack that looks more like a code manifest than a conversation.
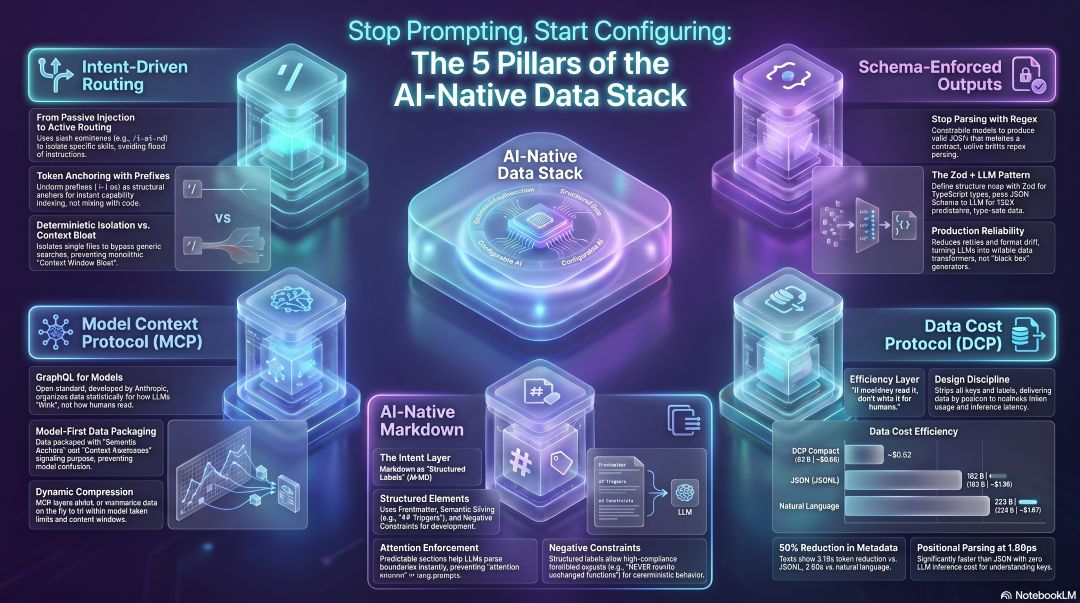
2. From Prose to Manifests: The Power of AI-Native Structured Labeling
The transition from a monolithic, unstructured .cursorrules file to modular .mdc and CLAUDE.md systems represents a fundamental shift in Context Architecture. By utilizing “Attention Slicing” and “Deterministic Isolation,” we ensure the model focuses exclusively on the logic required for the task at hand, ignoring irrelevant project bloat.
“The evolution from a single, unstructured text file to AI-Native Structured-Label formats represents a shift toward treating AI instructions as deterministic code configurations rather than conversational requests.”
Structured labeling enforces high compliance through three core mechanics:
- Frontmatter Frontloading: Uses explicit file patterns or paths to trigger specific rules, preventing “cross-domain prompt pollution.”
- Semantic Slicing: Employs predictable Markdown sections (e.g.,
## Triggers,## Constraints) so the LLM can parse boundaries instantly. - Negative Constraints: Explicitly defines forbidden outputs—such as “NEVER rewrite unchanged functions”—turning the AI into a deterministic execution engine.
3. The “i-” Prefix: Why Your AI Agent Needs a Naming Convention
Modern agentic workflows have migrated from passive context injection to active, intent-driven routing. The implementation of the “i-” prefix (standing for Intent, Instruction, or Impeccable) is an architectural optimization that enables Slash Commands (e.g., /i-ai-md). This allows the IDE to bypass generic, fuzzy search routines and isolate the specific file mapped to that command, solving the “Context Window Bloat” that plagues large repositories.
The “i-” prefix serves three critical roles in the Model Context Layer:
- Token Anchoring: Acts as a structural anchor that allows the LLM to cleanly tokenize boundaries, indexing custom skills as an explicit registry of capabilities.
- Token Conservation: Minimizes overhead in the system loop by using a short identifier to separate operational scripts from baseline code.
- Trigger Priority: Establishes “Intent-Driven Routing,” instructing the system to immediately prioritize a matching skill specification over general project rules whenever a slash command is detected.
4. GraphQL for Models: Why MCPs and DCP are Replacing JSON
We are witnessing the rise of the Model Context Layer—a protocol sitting between raw storage and the prompt. The Model Context Protocol (MCP) is an open standard developed by Anthropic and adopted by OpenAI to bridge the gap between traditional data systems and AI-native apps. If MCP is the request layer, the Data Cost Protocol (DCP) is the transport layer.
DCP operates on a radical “Schema-on-Wire” philosophy: “If no human reads the data, there’s no reason to write it in a human-readable format.” By declaring a schema once via a $S header and then sending data as positional values, DCP treats “position as meaning,” removing the need for repeated keys.
“Minify data before sending it to an AI… why have keys at all? If the consumer knows the schema, every key is a wasted token.”
By stripping the metadata overhead inherent in JSON, DCP achieves a ~50% reduction in data size, drastically lowering token costs and latency for machine-to-machine context exchange.
5. Markdown as the “Intent Layer”: Managing LLM Attention Cues
Markdown is the essential bridge between human intent (Layer 1) and AI implementation (Layer 3). While often viewed as a formatting tool, it serves a deeper technical purpose: Semantic Anchoring. Because LLMs process text as tokens, Markdown headings (##) provide clear token boundaries that act as “attention cues,” helping the model’s attention mechanism focus on relevant sections.
The impact on accuracy is massive. Consider a request for a weather app:
- Unstructured Description: When given a paragraph of text, the model often “guesses” at requirements, resulting in code that misses critical features like wind speed, humidity, and error handling.
- Structured (Markdown) Description: By using headings and lists, the structure enforces the inclusion of distinct items. The model identifies the specific user flow and error handling protocols because the structure itself communicates intent without ambiguity.
6. The Precision vs. Efficiency Trade-off
Optimizing your AI data stack requires choosing the right model for the specific data context. Benchmarking data reveals a stark divide between accuracy and resource conservation.
| Model | Strength | Weakness | Primary Use Case |
|---|---|---|---|
| Claude | Highest Accuracy (85%) | Slower / Higher Token Cost | Medical Records: Complex, hierarchical, high-stakes accuracy. |
| ChatGPT-4o | Best Token/Time Efficiency | Lower Accuracy in complex narratives | Receipts: Transactional, high-volume, cost-sensitive data. |
| Gemini | Balanced Performance | Variable performance in mixed-formats | General Purpose: Balanced RAG and tool-use tasks. |
Analysis: For hierarchical datasets like Medical Records where attribute completeness is non-negotiable, Claude’s precision justifies the cost. For high-volume, transactional data like Receipts, ChatGPT-4o’s 95% efficiency score makes it the superior choice for scaling production workflows.
7. Conclusion: Are You Speaking Your Model’s Language?
The shift from “Prompt Engineering” to “Context Architecture” is the hallmark of the mature AI stack. We can no longer afford to use human-centric data standards for machine-centric workflows. LLMs are not reading your documents for the prose; they are statistically learning patterns from the tokens you provide.
Are you still connecting an electric vehicle to a gas pump by forcing your AI to parse unstructured prose and verbose JSON? To unlock the next level of autonomous performance, you must embrace the machine-centric language of schemas, deterministic manifests, and positional data protocols. The future of AI isn’t in what you say—it’s in how you configure the context.